HTTP protocol
Hypertext Transfer Protocol (HTTP) is an application-layer protocol for transmitting hypermedia documents such as HTML. It is designed for communication between a web browser and a web server, but can also be used for other purposes. HTTP follows the classic client-server model, with the client opening a connection to make a request and then waiting for a response. HTTP is a stateless protocol, meaning that the server does not keep any data (state) between requests.
The target of an HTTP request is called a “resource”, which can be a document, an image, etc. Each resource is identified by a Uniform Resource Identifier (URI). The most common form of a URI is the Uniform Resource Locator (URL), which is known as a web address.
URL syntax
.jpg)
1. Scheme or protocol
The first element of a URL indicates which protocol the browser should use. This is usually the HTTP protocol or its secure version, HTTPS. The web requires the use of one of these two protocols, but browsers can also work with other protocols such as mailto: (to open an email client), ftp: (to handle file transfers), and so on.
2. Domain
www.example.com is the domain name. It indicates which web server is requested. Alternatively, it is possible to use an IP address directly, but due to its inconvenience, it is not often used on the web.
3. Port
The port specifies the technical “gateway” used to access the web server’s resources. It is usually omitted if the web server uses the standard HTTP protocol ports (80 for HTTP and 443 for HTTPS) to provide access to its resources. Otherwise, its specification is mandatory.
4. Path
/path/to/myfile.html is the path to the resource on the web server. In the early days of the web, a path like this represented the physical location of a file on the web server. These days, it’s mostly an abstraction.
5. Query
?key1=value1\&key2=value2 are additional parameters passed to the web server. These parameters are a list of key/value pairs separated by the & symbol. The web server can use these parameters to implement certain logic before returning the resource to the user.
6. Fragment
#SomewhereInTheDocument is an anchor to another part of the resource itself. An anchor is a markup within the resource that tells the browser to display the content located at that marked location. On an HTML document, for example, the browser will scroll to the point where the anchor is defined; on a video or audio document, the browser will try to go to the time that the anchor represents. The part after the #, also known as the fragment identifier, is never sent to the server with the request.
HTTP messages
HTTP messages are the way data is exchanged between a server and a client. There are two types of messages: a request sent by the client to initiate an action from the server (request), and a response from the server (response).
HTTP messages are composed of text information encoded in ASCII and arranged in a sequence of lines. In HTTP/1.1 and earlier versions of the protocol, these messages were sent openly over the connection. In HTTP/2, the message, which was once human-readable, is now divided into HTTP frames, providing optimization and performance improvements.
HTTP requests and responses share a similar structure and consist of:
· A start line, describing the request to be executed, or the success or failure status of the response received. This start line is always on a single line.
· An optional set of HTTP headers specifying the request or describing the body included in the message.
· An empty line indicating that all request metadata has been sent.
· An optional body containing data related to the request (such as the content of an HTML form) or the document associated with the response. The presence of the body and its size are determined by the start line and HTTP headers.
The initial line and headers of the message are collectively known as the request head, while its payload is known as the body.
.png)
Request structure
.png)
Requests consist of the following elements:
· An HTTP method, usually a verb like GET, POST or a noun like OPTIONS or HEAD, that defines the operation the client wants to perform. Typically, the client wants to retrieve a resource (via GET) or post data from an HTML form (via POST).
· The path of the resource to retrieve; the URL of the resource, stripped of elements that are obvious from the context, such as the protocol (http://), domain (here developer.mozilla.org), or TCP port (here 80).
· The version of the HTTP protocol.
· Optional headers that convey additional information about servers.
· Body for some methods such as POST, which contains the resource being sent.
Response structure
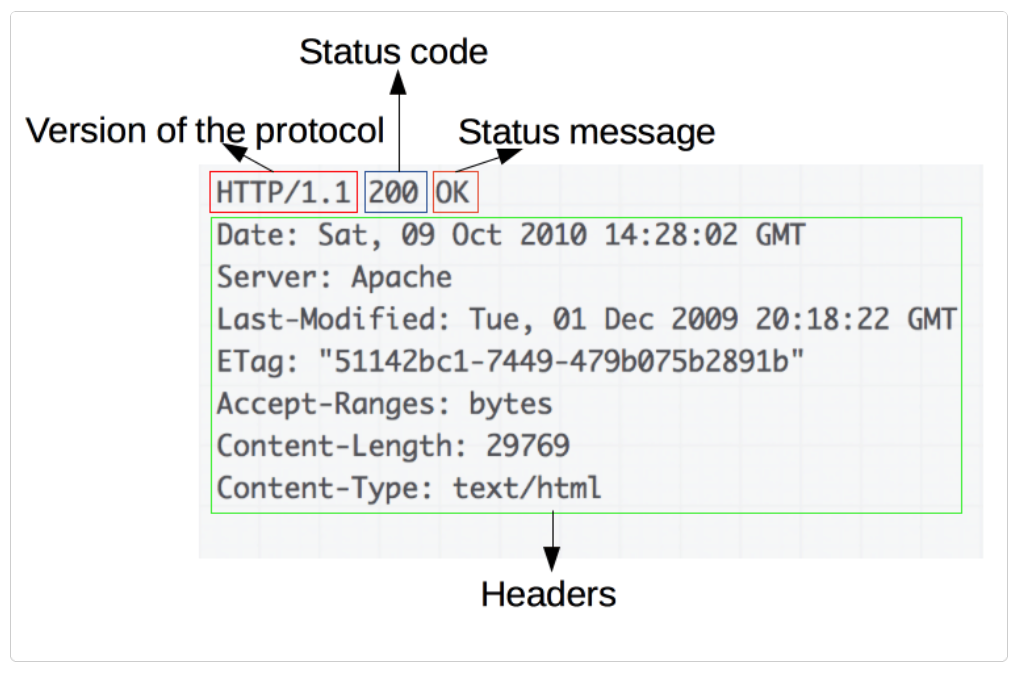
The responses consist of the following elements:
· The version of the HTTP protocol they follow.
· A status code indicating whether the request was successful or not and why.
· Status message, a short description of the status code.
· HTTP headers, similar to those of requests.
· An optional body containing the extracted resource.
Methods per HTTP request
HTTP defines a set of request methods to specify the desired action to be performed on a given resource. Each of them implements different semantics, but some common characteristics are shared by a group of them: e.g. a request method can be safe, idempotent, or cacheable.
GET
The GET method requires the specified resource to be provided. Requests using GET should only retrieve data.
This is said to be a safe method because it does not change the state of the resource. The GET method is idempotent. Therefore, calling this method multiple times will always produce the same result.
GET is the default request method. It sends data via a request header. The name-value pairs containing the data being passed are appended to the URL as a query string.
http://www.example.com:80/path/to/myfile.html?key1=value1\&key2=value2
Example for GET request:
.png)
Other characteristics of GET requests are:
· Remain in the browser history;
· Can be added to “bookmarked”;
· Can be cached;
· They have limitations on the length of the parameters passed;
· They should never be used when working with sensitive data;
· Should only be used for data retrieval.
POST
The POST method sends an object to the specified resource, often causing a state change or side effects on the server.
The HTTP POST method sends data to the server. The type of the request body is determined by the Content-Type header. The difference between PUT and POST is that PUT is idempotent: calling it once or several times in a row has the same effect, while successive identical POSTs can have additional effects, such as creating an order multiple times. A POST request is usually sent via an HTML form and results in a change on the server. In this case, the content type is selected by setting the appropriate value to the enctype attribute of the <form> element or the formenctype attribute of the <input> or <button> elements:
· application/x-www-form-urlencoded: keys and values are encoded in key-value pairs separated by ‘&’, with ‘=’ between key and value. Non-alphanumeric characters in both keys and values are percent-encoded: this is why this type is not suitable for use with binary data (use multipart/form-data instead)
· multipart/form-data: each value is sent as a block of data, with a user agent-defined delimiter separating each part.
· text/plain
In this method, the name-value pairs containing the transmitted data are sent via the request body.
.png)
Other characteristics of POST requests are:
· Cannot be bookmarked;
· No data length restrictions;
· They are not cached;
· Not saved in browser history.
PUT
The PUT request method creates a new resource or replaces the target resource with the data carried by the request. The difference between PUT and POST is that PUT is idempotent: calling it once or multiple times in succession has the same effect, while consecutive identical POST requests can have additional effects, similar to placing an order multiple times.
DELETE
The DELETE method is used to delete the specified resource.
PATCH
The PATCH method applies partial modifications to a resource. A PATCH request is considered a set of instructions on how to modify a resource, unlike PUT, which fully represents the resource.
PATCH is not necessarily idempotent, although it can be. Unlike PUT, which is always idempotent. The word “idempotent” means that any number of repeated identical requests will leave the resource in the same state. For example, if an auto-incrementing counter field is an integral part of the resource, then PUT will naturally overwrite it (since it overwrites everything), but this is not necessarily the case for PATCH. PATCH (like POST) can have side effects on other resources.
HEAD
The HEAD method requests a response identical to a GET request, but without the response body.
HEAD requires the headers that would be returned if the URL in the HEAD request were requested with the GET method. For example, if a URL could result in a large download, a HEAD request might read its Content-Length header to check the size of the file without actually downloading it.
CONNECT
The CONNECT method establishes a tunnel to the server identified by the target resource.
CONNECT initiates two-way communication with the requested resource. It can be used, for example, to access websites that use SSL (HTTPS). The client asks the HTTP proxy server to tunnel the TCP connection to the desired destination. The server then proceeds to make the connection on behalf of the client. Once the connection is established by the server, the proxy server continues to proxy the TCP stream to and from the client.
OPTIONS
The OPTIONS method describes the communication options for the target resource.
Requires enabled communication options for a given URL or server. The client can specify a URL with this method or an asterisk (*) to specify the entire server.
TRACE
The TRACE method performs a feedback test of the message along the path to the target resource, providing a useful debugging mechanism.
HTTP response status codes
HTTP response status codes indicate whether a particular HTTP request was completed successfully. Responses are grouped into five classes:
· Information responses (100 – 199)
· Successful responses (200 – 299)
· Redirection messages (300 – 399)
· Client error responses (400 – 499)
· Server error responses (500 – 599)
Някои по-важни кодове за състояние:
| Code | Description |
|---|---|
| Successful responses | |
| 200 OK | The request was successful. The resulting meaning of “success” depends on the HTTP method: GET: The resource is retrieved and passed in the message body. HEAD: The representation headers are included in the response without any message body. PUT or POST: The resource describing the result of the action is passed in the message body. TRACE: The message body contains the request message received from the server. |
| 201 Created | The request was successful and a new resource was created as a result. This is usually the response sent after POST requests or some PUT requests. |
| Redirection messages | |
| 301 Moved Permanently | The URL of the requested resource has been permanently changed. The new URL is provided in the response. |
| 302 Found | This response code means that the URI of the requested resource has changed temporarily. Additional changes to the URI may be made in the future. Therefore, the same URI should be used by the client in future requests. |
| 304 Not Modified | This is used for caching purposes. It tells the client that the response has not been modified, so the client can continue to use the same cached version of the response. |
| Client error responses | |
| 400 Bad Request | The server cannot or will not process the request due to something perceived as a client error (e.g., incorrect request syntax, invalid request message framing, or fraudulent request routing). |
| 401 Unauthorized | Indicates that the client request was not completed because valid credentials for the requested resource are missing. |
| 403 Forbidden | The client does not have permission to access the content, so the server refuses to provide the requested resource. Unlike 401 Unauthorized, the client’s identity is known to the server. |
| 404 Not Found | The server cannot find the requested resource. In a browser, this means that the URL is not recognized. In an API, this can also mean that the endpoint is valid, but the resource itself does not exist. Servers can also send this response instead of a 403 Forbidden to hide the existence of a resource from an unauthorized client. This response code is perhaps the most well-known due to its frequent occurrence on the web. |
| 405 Method Not Allowed | The request method is known to the server, but is not supported by the target resource. For example, the API may not allow a DELETE call to remove a resource. |
| Server error responses | |
| 500 Internal Server Error | The server has found itself in a situation it doesn’t know how to handle. |
| 501 Not Implemented | The request method is not supported by the server and cannot be processed. The only methods that servers should support (and therefore should not return this code) are GET and HEAD. |
| 502 Bad Gateway | This error response means that the server, while acting as a gateway to receive a response needed to process the request, received an invalid response. |
| 503 Service Unavailable | The server is not ready to process the request. Common causes are a server that is down for maintenance or overloaded. |